

Agent Orchestration Is the Hard Part
Everyone's building agents. Nobody's really talking about what happens when you need them to talk to each other.

I have an AI agent that wakes up at 6:30 every morning on a Mac Mini in my office. Her name is Aouda. She scans RSS feeds, scores content signals against my LinkedIn strategy, drafts posts, reviews her own drafts, revises them, and sends me a Slack summary — all before I’ve made coffee.
She’s not a chatbot, nor is she OpenClaw. She’s 60 TypeScript files, 9,500 lines of code, 40 tools, and a security architecture I spent days hardening. She monitors my inbox, drafts emails, watches my Docker containers, checks my calendar, makes appointments. I can text her on Telegram from my phone and she’ll spin up a Claude Code session on the Mac Mini and send me back a direct link for remote control so I can skirt API costs.
She’s genuinely useful.
She was the easy part.
The hard part was the moment she needed to coordinate with other systems. The moment her output became someone else’s input. The moment I went from “I built an agent” to “I built a system.”
That’s the orchestration layer, and I’m seeing so few talking about it beyond niche circles.
The Single-Agent Illusion
Here’s what every agent tutorial looks like: you give an LLM some tools, maybe a system prompt with a persona, and you let it run. It’s powerful. It’s fun. It works.
Until it doesn’t.
The first time I needed multiple agents to collaborate on the same codebase — one reading a roadmap, one decomposing tasks, one writing code, one reviewing it, one managing the merge queue — I realized I wasn’t building an agent team anymore. I was building a system, and systems have entirely different failure modes.
The demo version of AI is one agent, one task, one session. The production version is five agents, three handoffs, two quality gates, and a daemon running 24/7 with no human in the loop.
Those are not the same job.
UC Berkeley published a paper last week analyzing 1,600+ failure traces across seven multi-agent frameworks. Their finding: 79% of failures were coordination and specification problems — not model capability, not infrastructure, not prompting.

They built a whole taxonomy for this — the Multi-Agent Systems Failure Taxonomy (MAST) — and the breakdown is damning. Upwards of 40% of failures were specification issues. Another ~40% were inter-agent misalignment. The specific failure modes read like a postmortem of every bug I’ve shipped in the last week:
Conversation Reset (FM-2.1): An agent loses its context mid-task and starts over, undoing its own progress. I’ve watched this happen in real time — an agent 80% through a code review just... forgets what it was reviewing.
Task Derailment (FM-2.3): The agent drifts from the actual objective into circular, irrelevant work. This is the one where your dev agent decides to “refactor for consistency” instead of implementing the feature you actually asked for.
Clarification Failure (FM-2.2): The agent proceeds with wrong assumptions instead of asking for help — responsible for another ~12% of all system failures. This one’s insidious because the agent looks productive the whole time. It’s confidently building the wrong thing.
These aren’t “bugs” in the LLM. They’re emergent properties of the orchestration layer.
The agents were smart enough. The systems weren’t.
What Actually Breaks (and How to Fix It)
I’ll save you the suspense. It’s not the AI. The LLM calls work fine. What breaks is everything around them — the boring, un-demoable infrastructure that nobody puts in their Twitter thread.
Here are the four orchestration problems I’ve hit repeatedly, and the patterns I’ve landed on for each.
1. Auth and Credentials
The problem: Claude’s CLI needs macOS keychain access for OAuth. Sounds trivial. But my agents run as background daemons via LaunchAgent, and SSH sessions can’t access the keychain. I spent a full day debugging why an agent task — which worked perfectly when I ran it manually — silently failed at 10 AM on a Sunday.
This got worse with macOS Tahoe. The security command-line utility — the standard way to read keychain secrets — now frequently hangs indefinitely or returns exit code 36 when called from a LaunchAgent. Background processes don’t get a SecurityAgent session, and Tahoe’s tightened ACLs mean a secret stored by one binary path may be invisible to another. If you’re running agents as daemons on a Mac in 2026, this will bite you. It bit me.
The fix: launchctl kickstart instead of SSH. Every claude --print invocation has to go through the LaunchAgent so it inherits the GUI session’s keychain. I hit this bug weekly until I documented it in all caps: MUST use launchctl kickstart (not SSH nohup) — Claude CLI needs macOS keychain for OAuth.
The pattern: Any time an agent invokes another service that requires credentials, the execution context matters as much as the credentials themselves. Test your agents in the exact environment they’ll run in — not your terminal, not your SSH session. The daemon context.
This isn’t an AI problem. It’s a systems problem that just happens to have AI in the stack.
Those of us without engineering backgrounds are starting from behind the line, and all of this may sound like Latin. It sounded totally foreign to me a few months ago, too.
2. Error Handling: Stop or Continue?
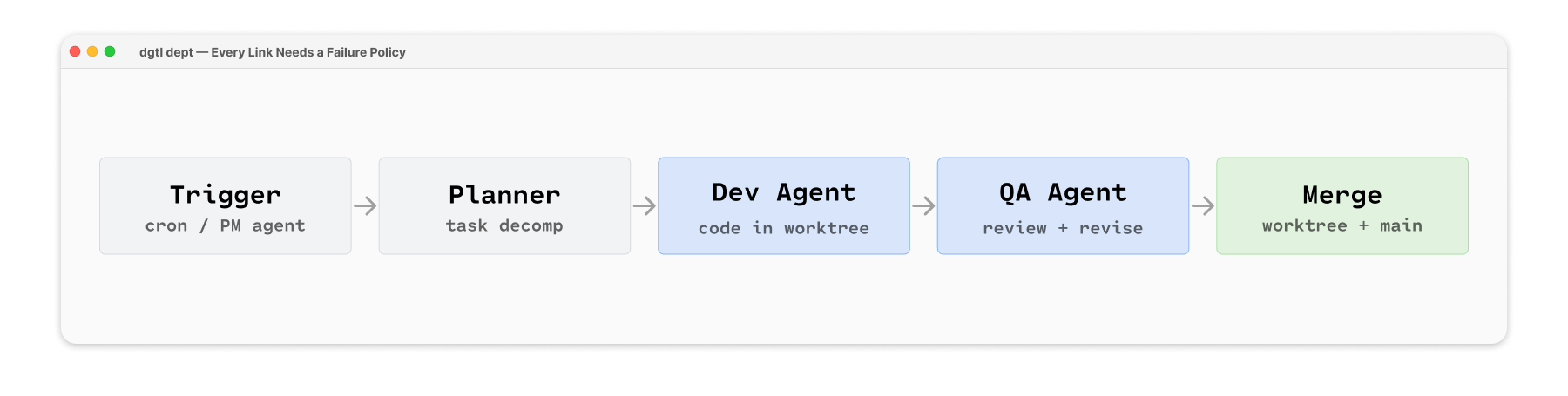
The problem: My orchestrator chains multiple agents together: a PM agent reads the roadmap and submits goals, a planner agent decomposes them into tasks, a dev agent writes the code, a QA agent reviews it. If the planner fails — bad input, parsing error, whatever — should the dev agent still pick up the last set of tasks?
In a single agent, the answer is obvious: crash and tell me about it. In an orchestrated chain, it depends. The dev agent can work on existing tasks even if no new ones get planned. Stale tasks are better than idle agents, but a corrupted task spec is worse than nothing — the dev agent will write code to the wrong spec and the QA agent won’t catch it.
The fix: Each handoff gets its own failure policy. The planner failing is a warning — log it, keep going, existing tasks are still valid. But if the dev agent produces corrupt output (syntax errors, failed tests, etc), hard stop. Do not pass go. Do not pass garbage to QA.
The pattern: Every handoff in a chain needs its own failure policy. Ask three questions at each link:
Can the next step run with stale/missing input?
Is stale output better than no output?
Will a failure here corrupt downstream work? My system has five links:
trigger → planner → dev → QA → mergeand each one answers those questions differently.
3. State Management
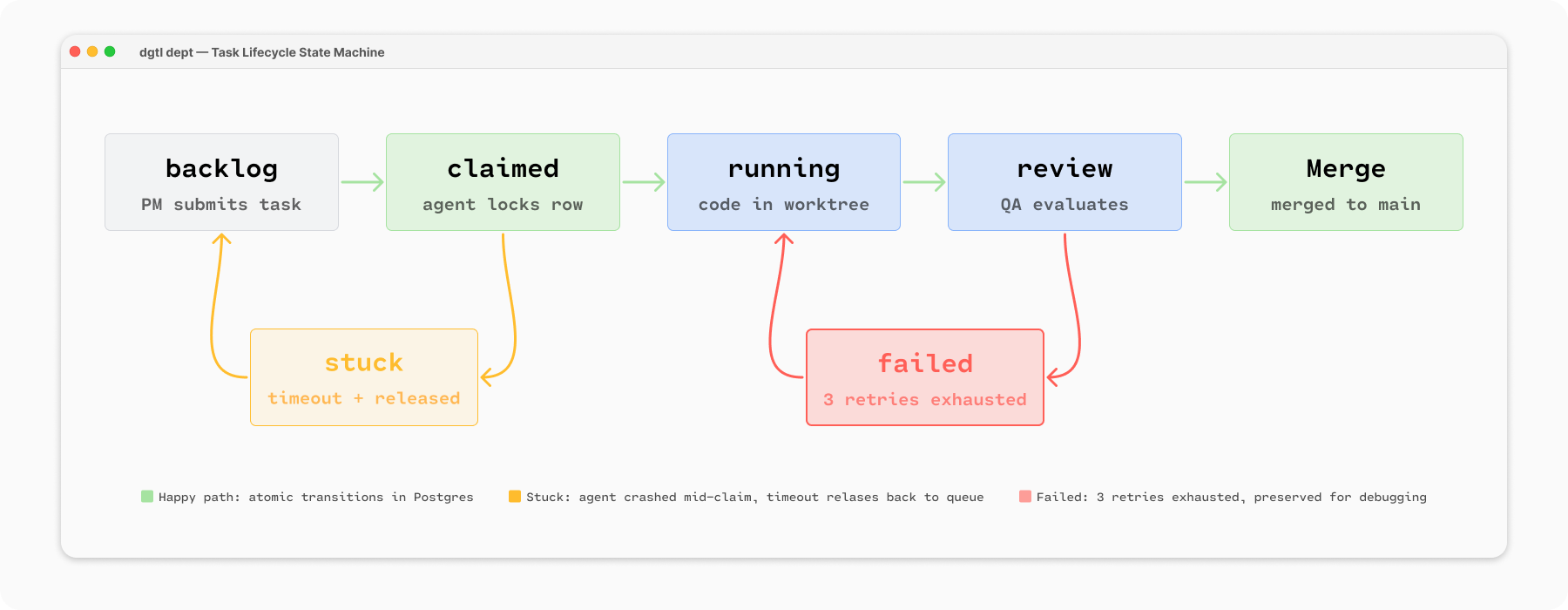
The problem: Every task in my system has a status:
backlog → claimed → running → review → done
The agent loop picks up backlog tasks, claims them, executes, and updates the status. Simple enough.
But what happens when an agent crashes between claiming a task and committing the code? The task stays claimed. Tomorrow’s loop sees it and skips it — it’s claimed, someone’s already working on it. But nobody actually is. Now you’ve got a stuck task and an agent that thinks it’s idle.
Or worse: two agents grab the same task in the same polling cycle. Now you’ve got conflicting branches, duplicate work, and a merge queue that can’t resolve the conflict.
The fix: SELECT FOR UPDATE SKIP LOCKED. Agents claim tasks atomically at the database level — if another agent already has it, the query returns nothing instead of blocking. And stuck tasks get a timeout: if a task stays claimed for longer than its trust tier’s max turns would allow (more on that in a moment), the system releases it back to the queue.
The pattern: State transitions should be atomic — claim the task and update the status in a single database transaction, so a crash produces a recoverable state rather than a phantom claim. This is solved-problem territory in software engineering — but the agent ecosystem hasn’t caught up yet. Most agent frameworks treat state as an afterthought, and honestly, most tutorials pretend it doesn’t exist.
I’m not the only one hitting this wall. A developer named Patrick runs a 5-agent system 24/7 on a Mac Mini — eerily similar hardware to mine — and independently landed on the same architecture: three files (current-task.json, context-snapshot.json, outbox.json) as the source of truth for every agent in the system. No framework. Just files and discipline. His conclusion mirrors mine: 80% of production agent failures trace to state management, not prompt quality.
4. Quality Gates
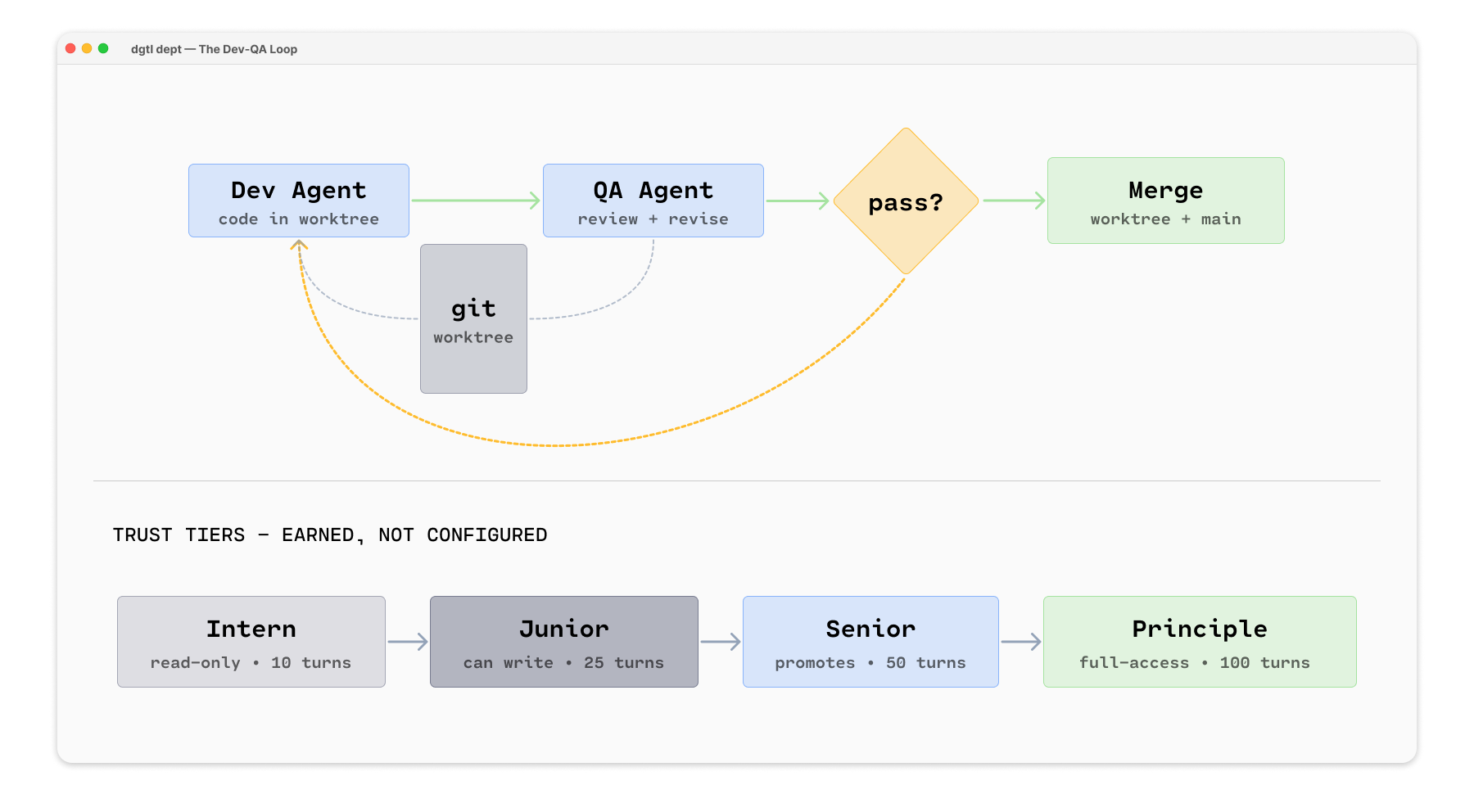
The problem: Here’s the loop my orchestrator runs for every dev task:
A dev agent writes code in an isolated git worktree
A QA agent reviews the code against the task spec
If QA says “revise,” the dev agent gets the code back with inline comments
Repeat up to 3 times
If it passes, it enters the merge queue
This is not one agent. This is three separate LLM calls with different system prompts, different evaluation criteria, and a control loop managing the transitions. The dev agent doesn’t know about the QA agent. The QA agent doesn’t remember the previous review. State flows through branches and task records, not through the model’s context.
The fix: The quality gate is the most important part of the system, but it’s the hardest to get right. The first time I let an agent write code with no QA gate, it reformatted my entire project structure “for consistency.” Another time, an agent passed its own QA review and merged code that broke the build — the QA criteria were checking for style and correctness but not for integration with the rest of the codebase.
I had to add trust tiers. New agents start as interns:
intern → junior → senior → principleThey earn promotion to junior, senior, and principal through consecutive successful completions — not set configuration. Three consecutive failures trigger a demotion. Trust isn’t a setting, it’s not unconditional. The agents have to earn it and prove they can keep it.
The pattern: Your quality gate is only as good as its criteria — and your trust model is only as good as its consequences. Build gates that check what actually matters (does this code integrate? does it pass tests?), not just what’s easy to check (does it look clean?). And give agents less access until they’ve proven they won’t trash the repo.
But trust tiers alone aren’t enough — and this is something I’m still building toward. The emerging standard in production AI governance is decision lineage (what I was calling the ‘judgement layer’ last week): every autonomous action generates a log documenting exactly why the decision was made, which data was accessed, and which policy was applied. Not just “agent committed code” but “agent committed code because task #47 specified this change, QA passed on attempt 2 of 3, and the agent’s trust tier authorized write access to this repo.”
The bigger idea here is Non-Human Identity (NHI) — giving every agent its own audited identity separate from your credentials. Right now, when my principal agent pushes code, it pushes as me. Even a principal-tier agent has to pass through a pre-push security gate that scans for secrets and PII before anything leaves the machine — but it’s still my name on the commit. That’s fine for a solo project. It’s a liability for anything regulated. The industry term for the alternative is “shadow autonomy” — agents acting under a human’s credentials with no way to distinguish who (or what) actually made the call. Decision lineage kills that ambiguity.
From Agent to Orchestrator
This is where claw.clip1 comes in.
After a couple weeks of building and using Aouda — and watching the orchestration question get bigger with every new capability — I started building a dedicated orchestrator. Not a framework. Not a library. A daemon that runs 24/7 on the same Mac Mini, managing teams of Claude Code agents.
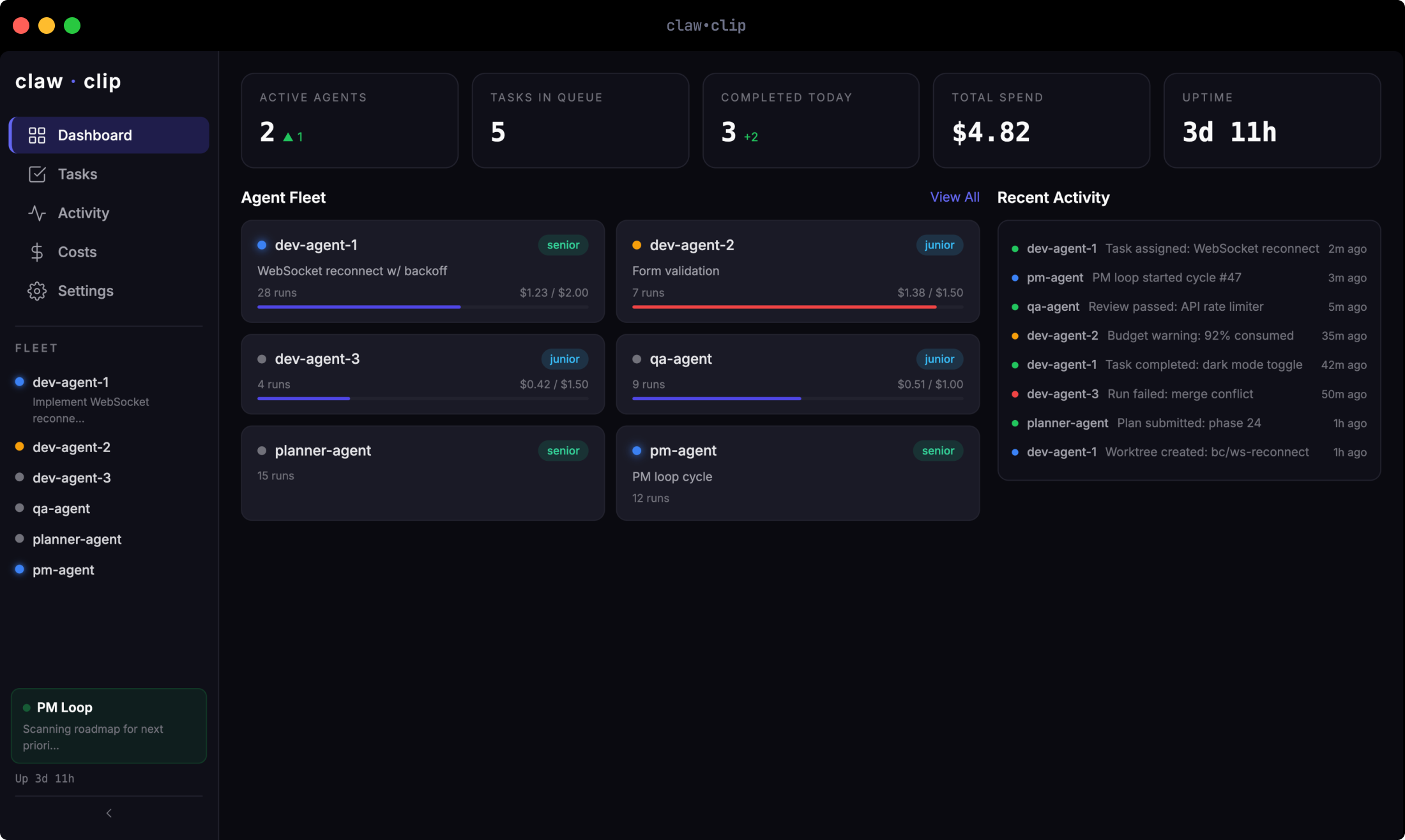
claw.clip assigns tasks from a priority queue. Agents claim work atomically — remember: SELECT FOR UPDATE SKIP LOCKED — so two agents never grab the same task. Trust tiers are invoked.
A PM agent runs every 30 minutes. It reads the roadmap — an actual ROADMAP.md file in the repo — and submits incomplete items to a planner agent, which decomposes them into 10-30 minute tasks. The PM doesn’t write code. It writes task specs. Other agents pick them up.
And here’s the part that still feels a little surreal:
claw.clip is building itself.
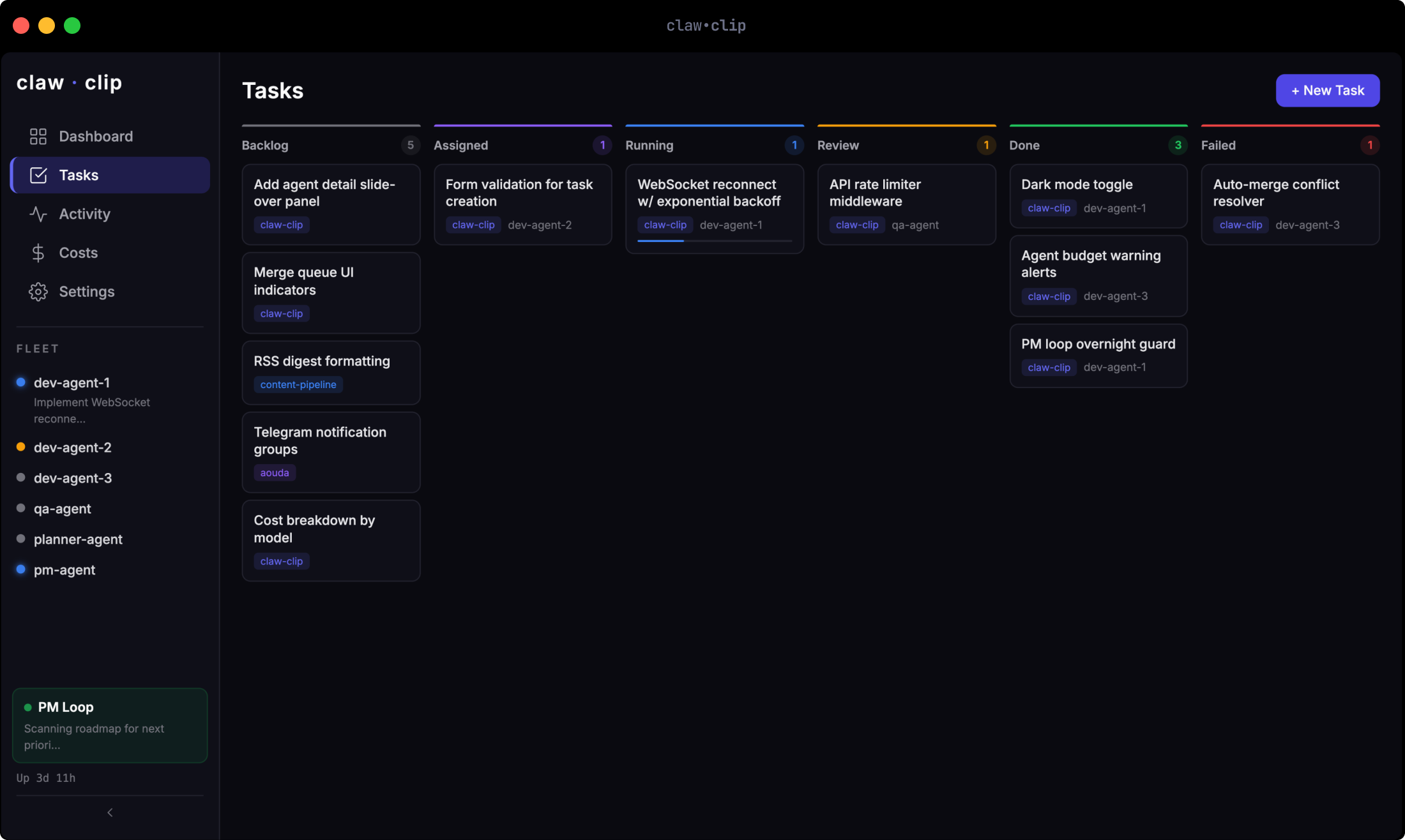
The agents working on improving the orchestrator are being orchestrated by the orchestrator. It tracks their costs, enforces their budgets, manages their merge queue, and promotes them when they deliver clean work.
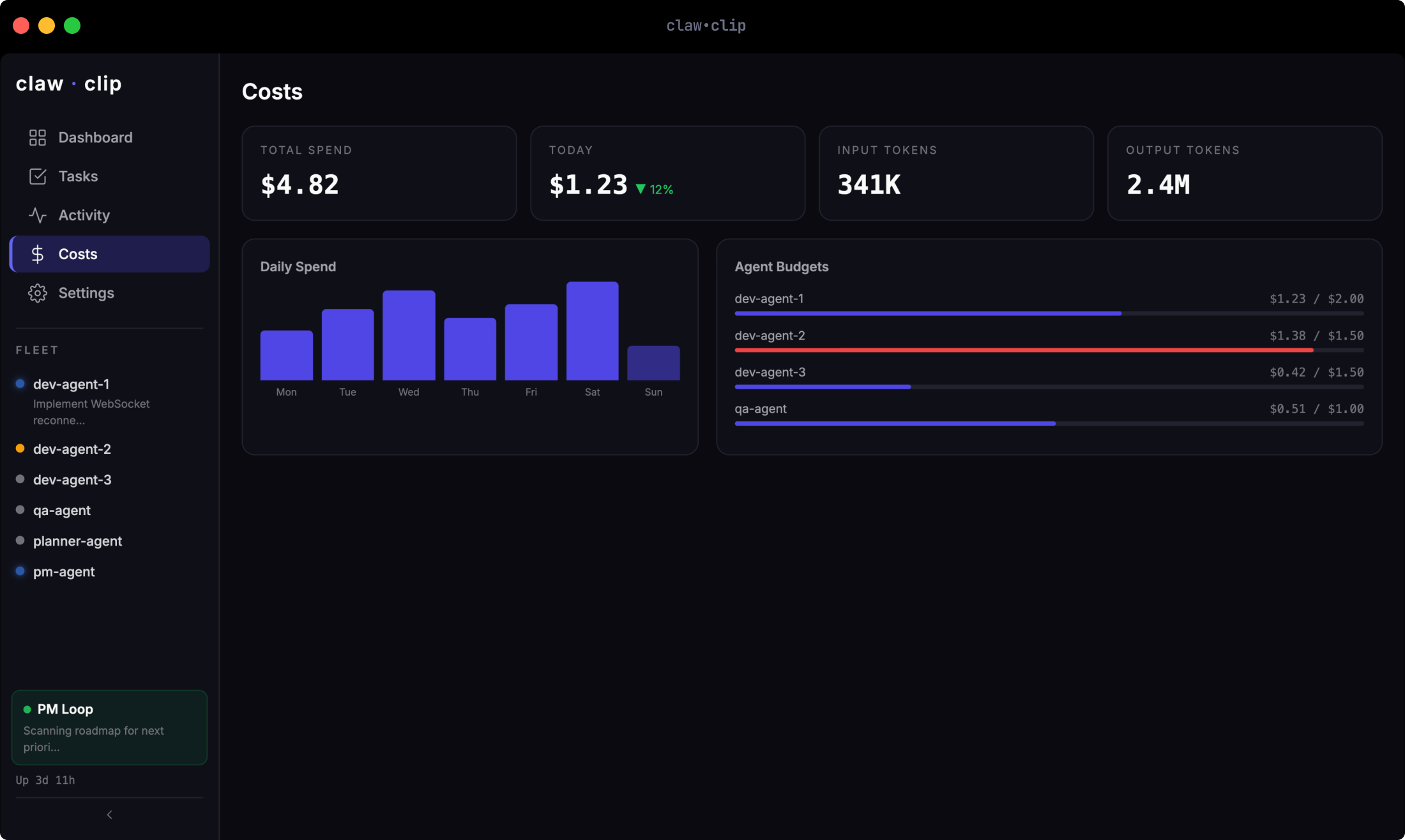
Is it overkill for a personal project? Potentially.
But it taught me something I couldn’t have learned from a tutorial: orchestration isn’t a feature you add to an agent. It’s a different discipline entirely.
Where This Goes Next: A2A and MCP
Right now, my orchestration is local. Agents talk through files, database rows, and git branches — all on one machine. That works for a solo operator. It doesn’t work when your agents need to collaborate with agents built by someone else.
The industry is converging on two protocols that solve this: Agent2Agent (A2A) and Model Context Protocol (MCP).
A2A is the messaging layer — it defines how agents find each other and hand off work. Every agent publishes an “Agent Card” (a machine-readable JSON file advertising its skills and auth requirements), and tasks move through a standardized lifecycle:
Submitted → Working → Completed or Failed
If that sounds familiar, it’s because it’s basically what my task queue already does, except it’s a universal standard instead of my personal PostgreSQL schema.
MCP is the tool layer — it standardizes how agents access tools and data sources. Instead of hardcoding every integration, an agent discovers available tools at runtime through MCP servers. I’m already using MCP for Aouda’s tool access. The gap is that my task output format doesn’t yet align with A2A’s Artifact schema — which means my agents can talk to each other, but they can’t talk to yours (yet).
That’s the next frontier. Local orchestration is table stakes. Interoperable orchestration is where this gets interesting.
The Career Reframe
Every tutorial, every demo, every “I built an AI agent in 20 minutes” post is about the single agent. Build it, ship it, done.
But production doesn’t work like that. Production is: what happens when this agent needs to hand off to that agent? What if the second one fails? What if the third one produces garbage and the fourth one can’t tell? What if the whole thing fails at 6:30 AM while nobody’s watching and all agents sit idle?
Three years ago the hot-topic hiring filter was “can you prompt an AI.” Three weeks ago it was ”can you design an agent”. I’m going to go ahead and say that a month from now, everyone will be talking about how you need to know how to build an orchestration layer.
Just watch.
It’s not a hypothetical, it’s starting to happen: “Agent orchestration specialist” is now a named job category. Eightfold AI called it the most important job of 2026. BMW is hiring a “Lead Agentic AI Orchestration” role. Job postings requiring agentic AI skills grew 986% between 2023 and 2024.
Prompt engineering is one thing, but systems engineering is entirely different animal. It’s state machines and error policies and trust hierarchies and quality gates. It’s set -uo pipefail vs set -euo pipefail. It’s knowing that SSH can’t access the keychain no matter how many times you forget to run LaunchAgent.
It’s the boring stuff, and it’s where the actual value lives. The good news is that this is learnable.


Did you enjoy this newsletter?
Please like it by clicking on the ❤️ at the very top or bottom of this post. This really helps get this newsletter recommended to Substack’s recommended shortlists.
Or, if you enjoyed this, learned something new, and it will help you in any way, reply and tell me about it. If you loved it, you can always treat me to a coffee.
The name is a nod to Paperclip, an open-source project that beat me to market with the same idea — orchestrating teams of AI agents with org structure, budgets, and governance. Great minds, etc. Where Paperclip is a cloud platform designed for enterprise teams running agents from any provider, claw.clip is a daemon — it runs 24/7 on bare metal, spawns Claude Code sessions directly via the CLI, and manages everything through files and git worktrees. It’s built for a solo operator on her own hardware, not a team on a cloud dashboard. I have much to do before it’s ready for a public repo, but follow along if you want to check it out as soon as it’s live.